Streaming Data: Training with FineWeb
In this tutorial, we will explore EIR’s built-in support for training with streaming data. Streaming allows us to train models on datasets that are too large to fit in memory or when data becomes available in real-time. We’ll demonstrate this using the FineWeb dataset, showing how to set up both the streaming server and the training configuration.
Note
This tutorial assumes you are familiar with the basics of EIR. While not required, it’s recommended to have gone through the basic tutorials first.
Note
See Streaming Data Hands-On Guide for more information on streaming data in EIR.
A - Overview
When working with streaming data in EIR, there are two main components:
A WebSocket server that streams the data
The EIR training configuration that connects to this stream
The server needs to implement a specific protocol that EIR understands, but once that’s set up, using streaming data is as simple as pointing to the WebSocket URL in your configuration.
B - Setting Up
For this tutorial, we’ll be using a simple server that streams text from the FineWeb dataset. Here’s the folder structure we’ll be working with:
eir_tutorials/i_scaling/01_streaming_data
├── fusion.yaml
├── globals.yaml
└── output.yaml
Let’s look at our configurations. The global config specifies basic training parameters:
basic_experiment:
batch_size: 256
memory_dataset: true
n_epochs: 100
output_folder: eir_tutorials/tutorial_runs/i_scaling/01_streaming
valid_size: 500
dataloader_workers: 4
evaluation_checkpoint:
checkpoint_interval: 500
n_saved_models: 1
sample_interval: 500
visualization_logging:
plot_skip_steps: 5000
For fusion, we use a simple pass-through configuration since we’re only doing sequence generation:
model_type: "pass-through"
The key configuration is the output config, where we specify our streaming source:
output_info:
output_source: ws://localhost:8000/ws
output_name: text_output
output_type: sequence
output_type_info:
max_length: 64
split_on: null
tokenizer: "bpe"
adaptive_tokenizer_max_vocab_size: 8192
sampling_strategy_if_longer: "uniform"
min_freq: 1
model_config:
embedding_dim: 128
model_init_config:
num_layers: 2
sampling_config:
generated_sequence_length: 64
n_eval_inputs: 1
manual_inputs:
- text_output: "This movie is the most"
- text_output: "Steven"
Note the output_source pointing to our WebSocket server. This tells EIR
to expect streaming data from this address.
C - Training
Before starting training, we need to ensure our streaming server is running.
The server will serve chunks of text from the FineWeb dataset. See section F
of this tutorial for the complete implementation of the server. To start it,
copy the content of the file text_streamer.py to a Python file and run it
with python text_streamer.py.
Once it’s running, in another terminal, we can start training:
eirtrain \
--global_configs eir_tutorials/i_scaling/01_streaming_data/globals.yaml \
--fusion_configs eir_tutorials/i_scaling/01_streaming_data/fusion.yaml \
--output_configs eir_tutorials/i_scaling/01_streaming_data/output.yaml
During training, EIR will connect to the streaming server and receive data in batches. Let’s look at some samples generated during training.
At iteration 500:
a edand and and s ed C, e, on the ed gitis is is to of and or , ing MBed is is is ed ed -(is or in in spis , Cbed ed ed and ens s s ed y y and sa sis was esed
This movie is the mosted for for ed B- to the e, er is of a Cor s and ing , s and pand Mand is , edis the is s and Mes (was was and ensor an , and or and is is and -or a a ss, s a
By iteration 2500, we can see improvement:
sude in the other and all it you know what he would do a work with a one for his own people I have not going to be more any resolar in a a fair of your same of the Bitonon Calling Paloo’s caught and as as some most most and
This movie is the most that it it you have to get you want to make your first of the own in refine, though about our one in its other day or instruction at all and unfell with a most reremarked outbay is no stirated of pandard was very be more
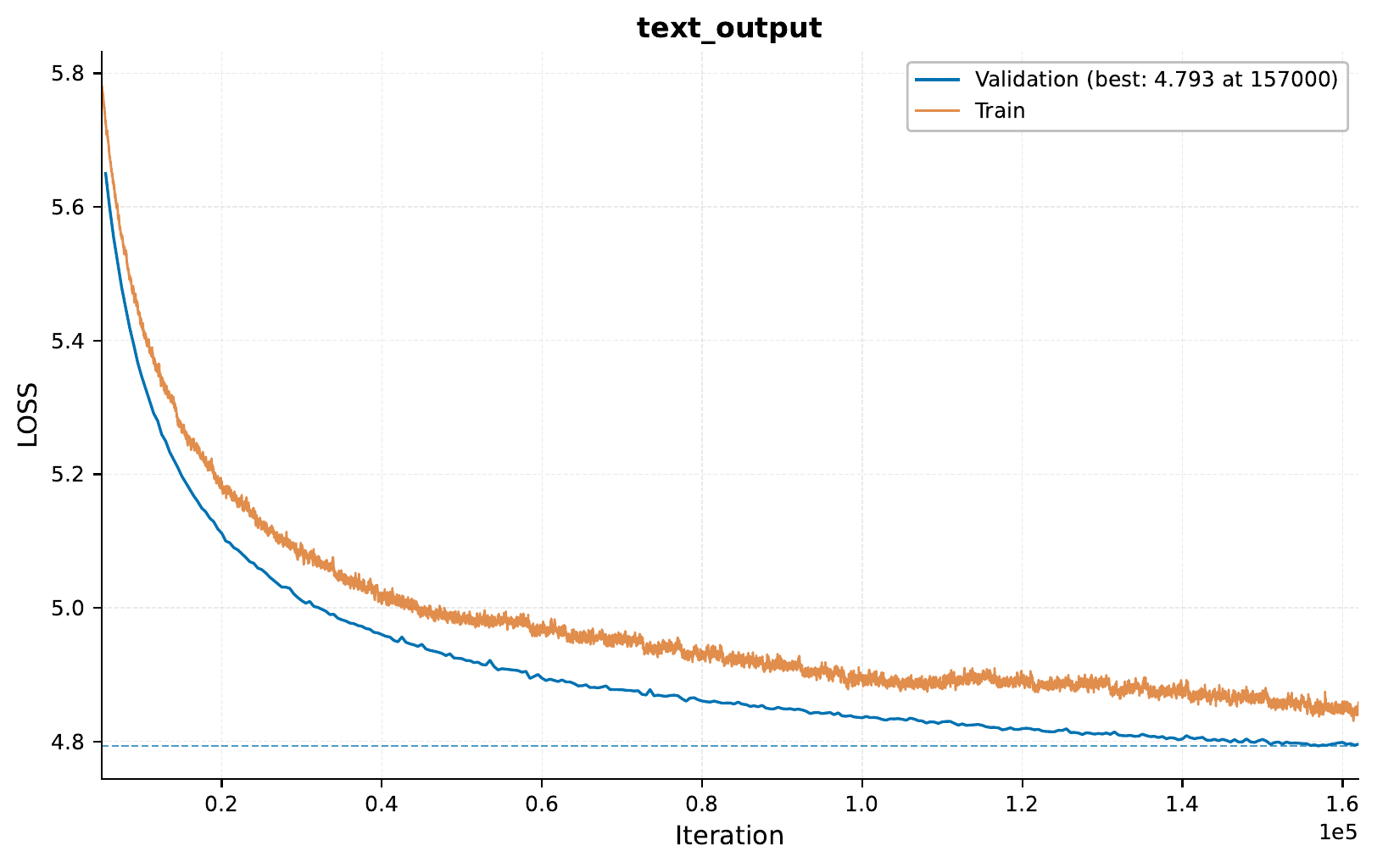
Here’s the training curve showing our progress:
D - Understanding the Streaming Server
The streaming server implements a simple WebSocket interface that EIR expects. Here’s a minimal example of what’s happening behind the scenes:
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_json()
if data["type"] == "getData":
batch = manager.get_sequence_batch(
batch_size=data["payload"]["batch_size"]
)
if not batch:
await manager.send_personal_message(
message={"type": "data", "payload": ["terminate"]},
websocket=websocket,
)
break
await manager.send_personal_message(
message={"type": "data", "payload": batch},
websocket=websocket,
)
F - Complete Server Implementation
Here’s the complete implementation of our streaming server, which you can use as a reference for implementing your own:
import argparse
import os
from threading import Lock
from typing import Any
from datasets import load_dataset
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from pydantic import BaseModel
from eir.setup.streaming_data_setup.protocol import PROTOCOL_VERSION
from eir.utils.logging import get_logger
logger = get_logger(name=__name__)
app = FastAPI()
class InputInfo(BaseModel):
type: str
shape: list[int] | None = None
class OutputInfo(BaseModel):
type: str
shape: list[int] | None = None
class DatasetInfo(BaseModel):
inputs: dict[str, InputInfo]
outputs: dict[str, OutputInfo]
class ConnectionManager:
def __init__(
self,
sequence_length: int = 256,
dataset_name: str = "HuggingFaceFW/fineweb",
dataset_split: str = "train",
max_iterations: int | None = None,
):
self.active_connections: dict[WebSocket, dict] = {}
self.global_position = 0
self._position_lock = Lock()
self.dataset = None
self.sequence_length = sequence_length
self.dataset_name = dataset_name
self.dataset_split = dataset_split
self.max_iterations = max_iterations
self.validation_ids: set[str] = set()
logger.info(f"Loading dataset {dataset_name} with split {dataset_split}")
logger.info(f"Using sequence_length={self.sequence_length}")
if self.max_iterations is not None:
logger.info(f"Will terminate after {self.max_iterations} iterations")
self.dataset_iterator = None
self.load_dataset()
async def connect(self, websocket: WebSocket):
try:
await websocket.accept()
handshake_message = await websocket.receive_json()
is_not_handshake = handshake_message["type"] != "handshake"
is_incompatible_version = handshake_message["version"] != PROTOCOL_VERSION
if is_not_handshake or is_incompatible_version:
await websocket.send_json(
{
"type": "error",
"payload": {"message": "Incompatible protocol version"},
}
)
await websocket.close()
return False
worker_id = handshake_message.get("worker_id", 0)
self.active_connections[websocket] = {
"current_position": 0,
"worker_id": worker_id,
}
await websocket.send_json(
{"type": "handshake", "version": PROTOCOL_VERSION}
)
return True
except Exception as e:
logger.error(f"Error in connect: {e}")
if websocket in self.active_connections:
del self.active_connections[websocket]
return False
def disconnect(self, websocket: WebSocket):
if websocket in self.active_connections:
del self.active_connections[websocket]
async def send_personal_message(self, message: dict, websocket: WebSocket):
await websocket.send_json(message)
async def broadcast(self, message: dict):
for connection in self.active_connections:
await connection.send_json(message)
def reset(self):
if self.dataset is not None:
self.dataset_iterator = iter(self.dataset)
self.global_position = 0
if self.max_iterations is not None:
logger.info(f"Reset: Will terminate after {self.max_iterations} iterations")
def load_dataset(self):
if self.dataset is None:
name = None
path = self.dataset_name
if path == "HuggingFaceFW/fineweb":
name = "sample-10BT"
self.dataset = load_dataset(
path,
name=name,
split="train",
streaming=True,
trust_remote_code=True,
)
self.dataset_iterator = iter(self.dataset)
def get_sequence_batch(self, batch_size: int) -> list[dict[str, Any]]:
if (
self.max_iterations is not None
and self.global_position >= self.max_iterations
):
logger.info(f"Reached max iterations ({self.max_iterations}), terminating")
return []
batch = []
min_words = 20
accumulated_text = []
accumulated_words = 0
with self._position_lock:
while len(batch) < batch_size:
try:
sample = next(self.dataset_iterator)
text = sample["text"].strip()
words = text.split()
word_count = len(words)
if word_count < min_words:
continue
if accumulated_words > 0:
accumulated_text.append("<|endoftext|>")
accumulated_text.extend(words)
accumulated_words += word_count
while accumulated_words >= self.sequence_length:
chunk_words = accumulated_text[: self.sequence_length]
chunk = " ".join(chunk_words)
sample_id = f"sample_{self.global_position}"
if sample_id not in self.validation_ids:
batch.append(
{
"inputs": {"text_output": chunk},
"target_labels": {
"text_output": {"text_output": chunk}
},
"sample_id": sample_id,
}
)
accumulated_text = accumulated_text[self.sequence_length :]
accumulated_words -= self.sequence_length
self.global_position += 1
if (
self.max_iterations is not None
and self.global_position >= self.max_iterations
):
logger.info(
f"Reached max iterations ({self.max_iterations}) "
f"during batch creation"
)
return batch
if len(batch) >= batch_size:
break
except StopIteration:
logger.info("Reached end of dataset stream, restarting iterator")
self.dataset_iterator = iter(self.dataset)
continue
if accumulated_words >= min_words and len(batch) < batch_size:
chunk = " ".join(accumulated_text)
sample_id = f"sample_{self.global_position}"
if sample_id not in self.validation_ids:
batch.append(
{
"inputs": {"text_output": chunk},
"target_labels": {"text_output": {"text_output": chunk}},
"sample_id": sample_id,
}
)
self.global_position += 1
if (
self.max_iterations is not None
and self.global_position >= self.max_iterations
):
logger.info(
f"Reached max iterations ({self.max_iterations}) after "
f"adding last chunk"
)
return batch
def create_manager():
sequence_length = int(os.getenv("SEQUENCE_LENGTH", "512"))
dataset_name = os.getenv("DATASET_NAME", "HuggingFaceFW/fineweb")
dataset_split = os.getenv("DATASET_SPLIT", "train")
max_iterations_str = os.getenv("MAX_ITERATIONS")
max_iterations = int(max_iterations_str) if max_iterations_str else None
logger.info(
f"Creating ConnectionManager with sequence_length={sequence_length}, "
f"dataset_name={dataset_name}, dataset_split={dataset_split}, "
f"max_iterations={max_iterations}"
)
return ConnectionManager(
sequence_length=sequence_length,
dataset_name=dataset_name,
dataset_split=dataset_split,
max_iterations=max_iterations,
)
manager = create_manager()
@app.websocket("/ws")
async def websocket_endpoint(websocket: WebSocket):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_json()
message_type = data.get("type")
if message_type == "getInfo":
dataset_info = DatasetInfo(
inputs={},
outputs={
"text_output": OutputInfo(type="sequence"),
},
)
await manager.send_personal_message(
message={"type": "info", "payload": dataset_info.model_dump()},
websocket=websocket,
)
elif message_type == "getData":
batch_size = data.get("payload", {}).get("batch_size", 32)
batch = manager.get_sequence_batch(batch_size=batch_size)
if not batch:
await manager.send_personal_message(
message={"type": "data", "payload": ["terminate"]},
websocket=websocket,
)
break
await manager.send_personal_message(
message={"type": "data", "payload": batch}, websocket=websocket
)
elif message_type == "setValidationIds":
validation_ids = data.get("payload", {}).get("validation_ids", [])
manager.validation_ids = set(validation_ids)
await manager.send_personal_message(
message={
"type": "validationIdsConfirmation",
"payload": {
"message": f"Received {len(validation_ids)} validation IDs"
},
},
websocket=websocket,
)
elif message_type == "reset":
manager.reset()
await manager.send_personal_message(
message={
"type": "resetConfirmation",
"payload": {"message": "Reset successful"},
},
websocket=websocket,
)
await manager.broadcast(
message={
"type": "reset",
"payload": {"message": "Reset command received"},
}
)
elif message_type == "status":
status_data = {
"active_connections": len(manager.active_connections),
"current_position": manager.global_position,
"validation_ids_count": len(manager.validation_ids),
}
if manager.max_iterations is not None:
status_data["max_iterations"] = manager.max_iterations
status_data["remaining_iterations"] = max(
0, manager.max_iterations - manager.global_position
)
await manager.send_personal_message(
message={"type": "status", "payload": status_data},
websocket=websocket,
)
elif message_type == "heartbeat":
await manager.send_personal_message(
message={"type": "heartbeat"}, websocket=websocket
)
except WebSocketDisconnect:
manager.disconnect(websocket)
finally:
manager.disconnect(websocket)
def main():
parser = argparse.ArgumentParser(description="Run the data streaming server")
parser.add_argument(
"--host", type=str, default="0.0.0.0", help="Host to run the server on"
)
parser.add_argument(
"--port", type=int, default=8000, help="Port to run the server on"
)
parser.add_argument(
"--max-iterations",
type=int,
default=None,
help="Maximum number of iterations before terminating (default: no limit)",
)
args = parser.parse_args()
if args.max_iterations is not None:
os.environ["MAX_ITERATIONS"] = str(args.max_iterations)
import uvicorn
uvicorn.run(app, host=args.host, port=args.port, ws_ping_timeout=3600)
if __name__ == "__main__":
main()
The server handles requests for data batches and streams them to EIR during training. This approach allows us to:
Train on datasets larger than memory
Process data in real-time
Implement custom data loading logic
Handle validation data separation
E - Conclusion
This tutorial has shown how to:
Configure EIR for streaming data
Set up a basic streaming server
Train a model using streamed data
Streaming is particularly useful when:
Working with large datasets
Processing real-time data
Implementing custom data loading logic
Thank you for reading!