Pretraining, Checkpointing and Continued Training
In this tutorial, we will be looking at how to use EIR to create pretrained models, and successively use them for continued training on the same data, as well as partially loading matching layers when changing the model architecture.
Note
This tutorial assumes you are familiar with the basics of EIR, and have gone through previous tutorials. Not required, but recommended.
A - Data
We will be using the same dataset we used in the Sequence Tutorial: Movie Reviews and Peptides: the IMDB reviews dataset, and we will be repeating the same task as before, i.e., sentiment classification.
See here for more information about the data. To download the data, use this link.
After downloading the data, the folder structure should look like this:
eir_tutorials/e_pretraining/01_checkpointing
├── conf
│ ├── imdb_fusion.yaml
│ ├── imdb_globals.yaml
│ ├── imdb_input.yaml
│ └── imdb_output.yaml
└── data
└── IMDB
├── conf
├── imdb_labels.csv
├── IMDB_Reviews
└── imdb.vocab
B - Training a Model From Scratch
Training follows the same approach as we have seen on other tutorials, starting with the configurations.
The global config sets the universal parameters for training:
basic_experiment:
batch_size: 64
dataloader_workers: 0
device: cpu
memory_dataset: true
n_epochs: 5
output_folder: eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing
valid_size: 1024
evaluation_checkpoint:
checkpoint_interval: 200
n_saved_models: 1
sample_interval: 200
optimization:
lr: 0.0005
optimizer: adabelief
visualization_logging:
plot_skip_steps: 0
The input config outlines the IMDB dataset’s specific structure:
input_info:
input_source: eir_tutorials/e_pretraining/01_checkpointing/data/IMDB/IMDB_Reviews
input_name: captions
input_type: sequence
input_type_info:
max_length: 64
split_on: " "
tokenizer: null
sampling_strategy_if_longer: "uniform"
model_config:
embedding_dim: 64
For the output configurations:
output_info:
output_source: eir_tutorials/e_pretraining/01_checkpointing/data/IMDB/imdb_labels.csv
output_name: imdb_output
output_type: tabular
output_type_info:
target_cat_columns:
- Sentiment
Here is the command for training:
eirtrain \
--global_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_globals.yaml \
--input_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_input.yaml \
--fusion_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_fusion.yaml \
--output_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_output.yaml \
--imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing/
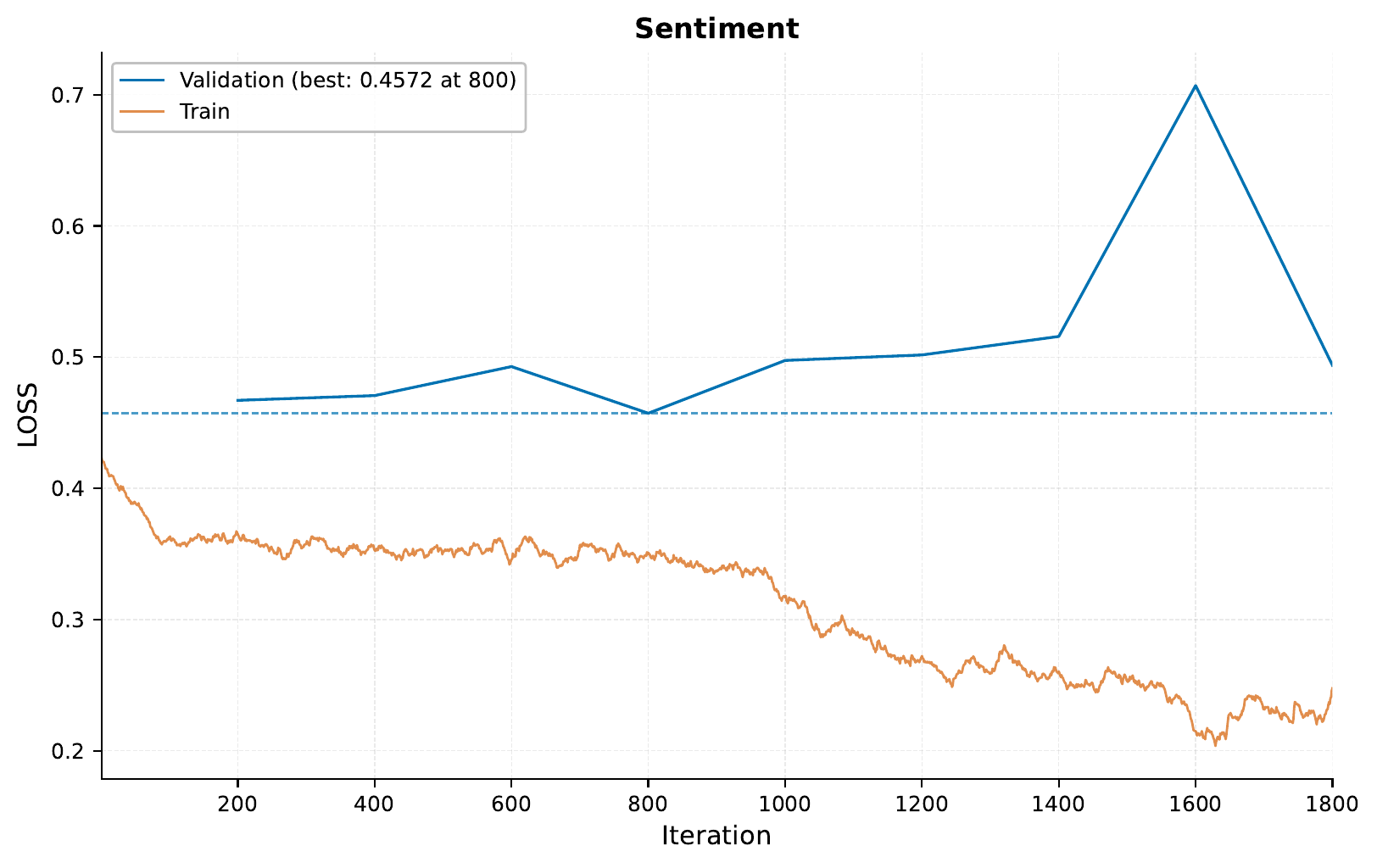
Training Results:

So, these training results are nothing too much out of the ordinary, with the training and validation loss both decreasing as training goes on.
C - Continuing Training from a Checkpoint
Often, you might want to resume training from a previously saved checkpoint.
This can be especially useful for reasons such as
fine-tuning the model on a different dataset,
or resuming a long-running training process after interruption.
For this, we can use the pretrained_checkpoint argument in the global config.
Here is how we can do that:
eirtrain \
--global_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_globals.yaml \
--input_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_input.yaml \
--fusion_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_fusion.yaml \
--output_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_output.yaml \
--imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing_imdb_from_pretrained_global \
--imdb_globals.model.pretrained_checkpoint=eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing/saved_models/01_checkpointing_checkpoint_1800_perf-average=0.7718.pt
Important
The argument points towards a saved model file from a previous experiment, and the loading process relies on some saved data from the previous experiment. Therefore, it will likely not work if you try to load a checkpoint that has been moved from the relative path it was saved in.
Training Results After Continued Training:
From the training curve, it’s evident how the model essentially picks up from where it left off as the training loss is already quite low from the start, compared to the previous training from scratch.
D - Partial Loading of Matching Layers
There are scenarios where you might change the
architecture of your model but still
want to use the pretrained weights for the layers that match.
This can be achieved by setting the strict_pretrained_loading
argument to False in the global config.
Below, we will change the dimension of the fully connected layers in the fusion module, but keep the rest of the model the same.
eirtrain \
--global_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_globals.yaml \
--input_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_input.yaml \
--fusion_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_fusion.yaml \
--output_configs eir_tutorials/e_pretraining/01_checkpointing/conf/imdb_output.yaml \
--imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing_imdb_from_pretrained_global_non_strict \
--imdb_fusion.model_config.fc_task_dim=64 \
--imdb_globals.model.pretrained_checkpoint=eir_tutorials/tutorial_runs/e_pretraining/01_checkpointing/saved_models/01_checkpointing_checkpoint_1800_perf-average=0.7718.pt \
--imdb_globals.model.strict_pretrained_loading=False
Results After Partial Loading and Continued Training:

Notice how the training loss starts at a similar value as when training from scratch, but then more quickly decreases to a lower value, indicating that the model can still benefit from the pretrained weights in the unchanged layers.
Thank you for reading!