Sequence Tutorial: Movie Reviews and Peptides
In this tutorial, we will be training models using discrete sequences as inputs. Here, we will be doing two tasks. Firstly, we train a model to classify positive vs. negative sentiment in the IMDB reviews dataset. Secondly, we will train another model to detect anticancer properties in peptides using the anticancer peptides dataset.
Note that this tutorial assumes that you are already familiar with the basic functionality of the framework (see Genotype Tutorial: Ancestry Prediction).
A - IMDB Reviews
A1 - IMDB Setup
For this first task, we will do a relatively classic NLP task, where we train a model to predict sentiment from IMDB reviews, see here for more information about the data. To download the data and configurations for this part of the tutorial, use this link.
Here we can see an example of one review from the dataset.
$ cat IMDB/IMDB_Reviews/3314_1.txt
Reading through all these positive reviews I find myself baffled.
How is it that so many enjoyed what I consider to be a woefully bad adaptation
of my second favourite Jane Austen novel? There are many problems with the film,
already mentioned in a few reviews; simply put it is a hammed-up, over-acted,
chintzy mess from opening credits to butchered ending.<br /><br />While many
characters are mis-cast and neither Ewan McGregor nor Toni Collette puts in a
performance that is worthy of them, the worst by far is Paltrow. \
I have very much enjoyed her performance in some roles, but here she is
abominable - she is self-conscious, nasal, slouching and entirely disconnected
from her characters and those around her. An extremely disappointing effort -
though even a perfect Emma could not have saved this film.
Whatever movie this review is from, it seems that the person certainly did not enjoy it! This is fairly obvious for us to see, now the question is if we train a model to do the same.
As in previous tutorials, we will start by defining our configurations.
attribution_analysis:
attributions_every_sample_factor: 4
compute_attributions: true
max_attributions_per_class: 512
basic_experiment:
memory_dataset: true
n_epochs: 25
output_folder: eir_tutorials/tutorial_runs/a_using_eir/tutorial_03_imdb_run
valid_size: 0.1
evaluation_checkpoint:
checkpoint_interval: 500
n_saved_models: 1
sample_interval: 500
Note
You might notice that in the global configuration in this tutorial, we have a couple
of new parameters going on. Namely the compute_attributions, max_attributions_per_class and
attributions_every_sample_factor. These are settings related to computing attributions
so we can interpret/explain how our inputs influence the model outputs. For more
information, check out the Configuration API Reference reference.
input_info:
input_source: eir_tutorials/a_using_eir/03_sequence_tutorial/data/IMDB/IMDB_Reviews
input_name: imdb_reviews
input_type: sequence
input_type_info:
sampling_strategy_if_longer: "uniform"
max_length: 64
split_on: " "
min_freq: 10
tokenizer: "basic_english"
tokenizer_language: "en"
model_config:
model_type: sequence-default
embedding_dim: 64
position: embed
pool: avg
model_init_config:
num_heads: 2
dropout: 0.2
output_info:
output_source: eir_tutorials/a_using_eir/03_sequence_tutorial/data/IMDB/imdb_labels.csv
output_name: imdb_output
output_type: tabular
output_type_info:
target_cat_columns:
- Sentiment
Tip
There are a lot of new configuration options going on here, head over to the Configuration API Reference reference for more details.
Now with the configurations set up, our folder structure should look like this:
eir_tutorials/a_using_eir/03_sequence_tutorial/
├── a_IMDB
│ └── conf
│ ├── 03a_imdb_globals.yaml
│ ├── 03a_imdb_input.yaml
│ └── 03a_imdb_output.yaml
└── data
└── IMDB
├── conf
├── imdb_labels.csv
├── IMDB_Reviews
└── imdb.vocab
A2 - IMDB Training
As before, we can train a model using eirtrain:
eirtrain \
--global_configs eir_tutorials/a_using_eir/03_sequence_tutorial/a_IMDB/conf/03a_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/03_sequence_tutorial/a_IMDB/conf/03a_imdb_input.yaml \
--output_configs eir_tutorials/a_using_eir/03_sequence_tutorial/a_IMDB/conf/03a_imdb_output.yaml
This took around 20 minutes to run on my laptop, so this is a good chance to take a nap or do something else for a while!
Looking at the accuracy, I got the following training/validation results:

Perhaps not great, but not too bad either! Especially since we are using a relatively short sequence length.
Note
Here we are using a transformer based neural network for the training, however do not underestimate the power of classical, more established methods. In fact, simpler, non neural-network based methods have attained better accuracy that what we see above! If you have some time to kill, try playing with the hyper parameters a bit to see how they affect the performance.
A3 - IMDB Interpretation
Now remember those new flags we used in the global configuration,
compute_attributions and friends? Setting those will instruct the
framework to compute and analyze
how the inputs influence the model
towards a certain output. In this case,
the attributions can be found in the
imdb_sentiment/results/Sentiment/samples/<every_2000_iterations>/attributions
folders. Behind the scenes,
the framework uses integrated gradients,
implemented in the fantastic the Captum library,
to compute the attributions.
Firstly, let’s have a look at the words that had the biggest influence towards a Positive and Negative sentiment.

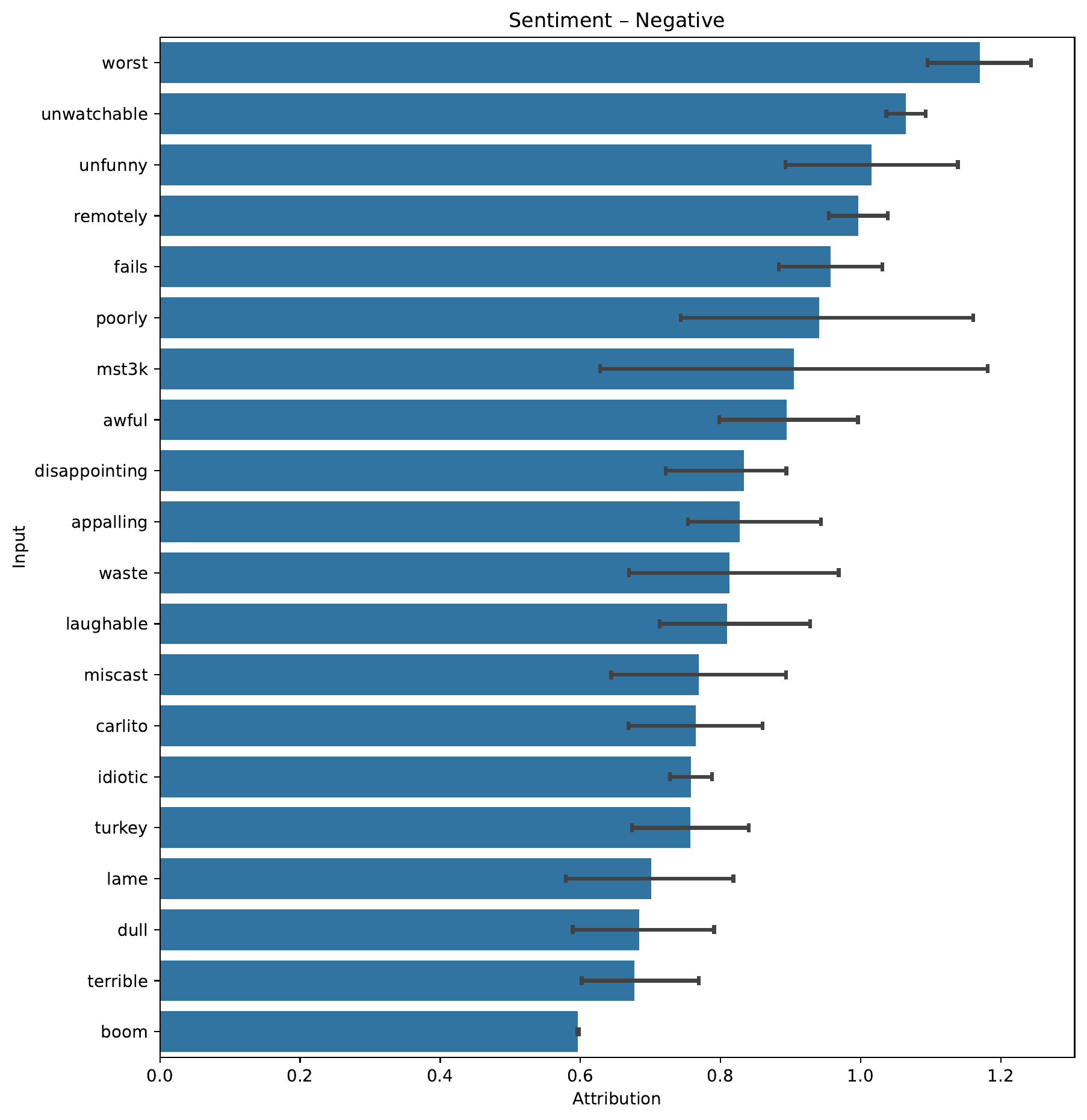
Note
Which tokens are included in this plot and how they are sorted is based both on the average and 95% confidence interval of the attribution. The raw values are also stored, in case you want to do your own analysis. The CIs represent the 95% confidence interval after 1,000 bootstrap samples.
So fortunately, it seems indeed that our model learned some relevant things! When training on sequences, the framework will also by default save attributions towards the relevant label for 10 single samples, here is one such example, where we look at the attributions towards a positive sentiment.
| ID | True Label | Attribution Score | Token Importance |
|---|---|---|---|
| the film is bad . there is no other way to say it . the story is weak and outdated , especially for this country . i don ' t think most people know what a walker is or will really care . i felt as if i was watching a movie from the 70 ' s . the subject was just not believable | |||
| the plot for descent , if it actually can be called a plot , has two noteworthy events . one near the beginning - one at the end . together these events make up maybe | |||
| like one of the previous commenters said , this had the | |||
| somewhat funny and well-paced action thriller that has jamie foxx as a hapless , fast-talking hoodlum who is chosen by an overly demanding u . s . treasury agent ( david morse ) to be released on the streets of new york to find a picky computer | |||
| the worst movie i have seen since | |||
| i had no idea what the film is about before i saw it because tashan only had teaser trailers while it was being promoted . so i asked my friends if they knew anything about it and they said that it is the directorial debut of vijay krishna acharya who wrote the screenplays for dhoom 1 & 2 and saif ali khan ' s | |||
| what ' s inexplicable ? firstly , the hatred towards this movie . it may not be the greatest movie of all time , but gimme a break , it got 11 oscars for a reason , it made eighteen hundred million dollars for a reason . it ' s a damn good movie . which brings to the other inexplicable aspect of it | |||
| another aussie masterpiece , this delves into the world of the unknown and the supernatural , and it does very well . it doesn ' t resort to the big special effects overkill like american flicks , it focuses more on emotional impact . a relatively simple plot that rebecca | |||
| i grew up on the ' superman ii ' theatrical version ( | |||
| i admit to being somewhat jaded about the movie genre of a young child | |||
That concludes the NLP specific part of this tutorial, next we will apply the same approach but for biological data!
B - Anticancer Peptides
B1 - Anticancer Peptides Setup
Modelling on language like we did above is both fun and relatable, but now we try something a bit more niche. For this second part of the tutorial, we will use the framework to predict anti breast cancer properties of peptides (a peptide is basically a short protein sequence). See here for more information about the dataset. To download the data and configurations for this part of the tutorial, use this link.
Again, let’s take a quick look at one sample we are going to be modelling on:
Here we can see an example of one review from the dataset.
$ cat Anticancer_Peptides/breast_cancer_train/1.txt
AAWKWAWAKKWAKAKKWAKAA
So immediately we can see that this is fairly different from our movie reviews,
let’s see how it goes with the modelling part.
As always,
we start with the configurations.
You might notice a new option in the global configuration,
weighted_sampling_columns.
This setting controls
which target column to use for weighted sampling,
and the special keyword all
will take an average across
all target columns.
In this case we have only one (“class”),
so it just accounts for that one.
This can be useful for this dataset
as it is quite imbalanced w.r.t. target labels,
as you will see momentarily.
attribution_analysis:
attributions_every_sample_factor: 3
compute_attributions: true
max_attributions_per_class: 512
basic_experiment:
batch_size: 32
memory_dataset: true
n_epochs: 500
output_folder: eir_tutorials/tutorial_runs/a_using_eir/tutorial_03_anti_breast_cancer_peptides_run
valid_size: 0.25
evaluation_checkpoint:
checkpoint_interval: 200
n_saved_models: 1
sample_interval: 200
training_control:
early_stopping_buffer: 2000
weighted_sampling_columns:
- all
Note
You might notice that we use a large validation set here. This a similar situation as in Tabular Tutorial: Nonlinear Poker Hands, where we used a manual validation set to ensure that we have all classes present in the validation set. Here, we take the lazier approach and just make the validation set larger. Currently the framework does not handle having a mismatch in which classes are present in the training and validation sets.
Notice that the input configuration is slightly different. For example, as we are not dealing with natural language, we do not split on whitespace anymore, but rather on “”.
input_info:
input_source: eir_tutorials/a_using_eir/03_sequence_tutorial/data/Anticancer_Peptides/breast_cancer_train
input_name: peptide_sequences
input_type: sequence
input_type_info:
max_length: "max"
split_on: ""
min_freq: 1
model_config:
model_type: sequence-default
position: embed
embedding_dim: 32
pool: avg
model_init_config:
num_heads: 8
dropout: 0.2
interpretation_config:
num_samples_to_interpret: 30
interpretation_sampling_strategy: random_sample
output_info:
output_source: eir_tutorials/a_using_eir/03_sequence_tutorial/data/Anticancer_Peptides/breast_cancer_labels.csv
output_name: peptides_output
output_type: tabular
output_type_info:
target_cat_columns:
- class
B1 - Anticancer Peptides Training
For the peptide data, the folder structure should look something like this:
eir_tutorials/a_using_eir/03_sequence_tutorial/
├── b_Anticancer_peptides
│ └── conf
│ ├── 03b_peptides_globals.yaml
│ ├── 03b_peptides_input.yaml
│ └── 03b_peptides_output.yaml
└── data
└── Anticancer_Peptides
├── breast_cancer_labels.csv
└── breast_cancer_train
As before, we run:
eirtrain \
--global_configs eir_tutorials/a_using_eir/03_sequence_tutorial/b_Anticancer_peptides/conf/03b_peptides_globals.yaml \
--input_configs eir_tutorials/a_using_eir/03_sequence_tutorial/b_Anticancer_peptides/conf/03b_peptides_input.yaml \
--output_configs eir_tutorials/a_using_eir/03_sequence_tutorial/b_Anticancer_peptides/conf/03b_peptides_output.yaml
As the data is imbalanced, we will look at the MCC training curve:
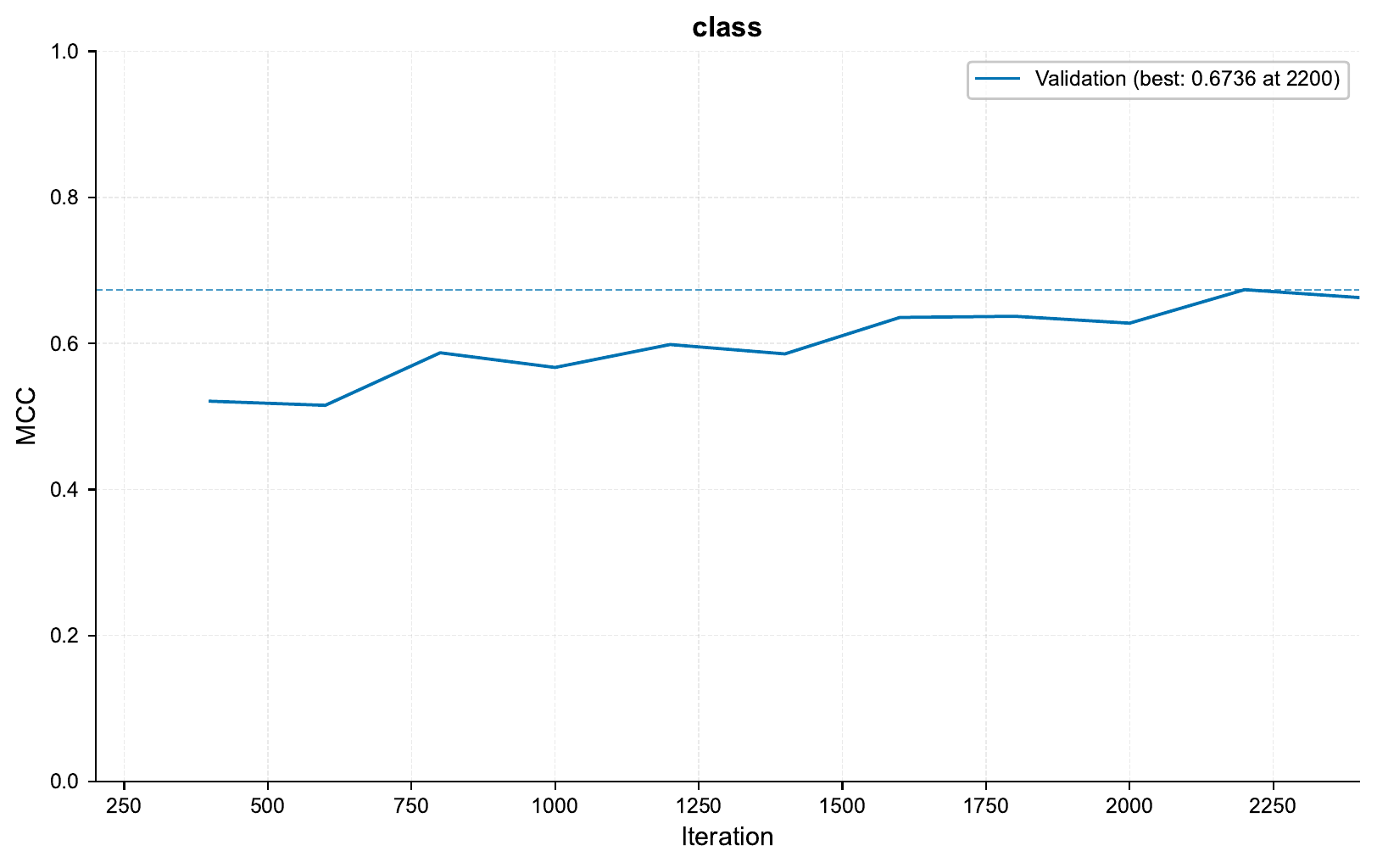
Checking the confusion matrix at iteration 2000, we see:

Looking at the training curve, we see that we are definitely overfitting quite a bit! We could probably squeeze out a better performance by playing with the hyperparameters a bit, but for now we will keep going!
As before, let’s have a look at the attributions. In this case we will check attributions towards the moderately active class:

In this case, it seems that there is a high degree of uncertainty in the attributions, as the confidence intervals are quite large. This is likely due to the fact that the dataset is quite imbalanced, and there are few samples of moderately active peptides in the validation set.
Looking at an example of single moderately active sample and how its inputs influence the model towards a prediction of the moderately active class, we see:
| ID | True Label | Attribution Score | Token Importance |
|---|---|---|---|
| T T D E I N A M D K A L I L Y T | |||
| L P H F Y E L F S L W A | |||
| L L N I R R E F I E K Y | |||
| A Q T S R W A A M Q I G M S F I S A Y | |||
| F L L S K A K D A K S S A E G A V | |||
| N P G Q A I W L G E F S K R H | |||
| F E V I D T I K A A V E N A | |||
| S G R F W K L Y I E A E I K A | |||
| D A R A K K L L D K W A K W I N G | |||
| N P A R A L Y Q T V R E L I E N S L D A | |||
| G E A Y L L L E R Y V A F L R A | |||
| T E V Y Q I L N R V S | |||
| N P A Q Y L A Q H E Q L L | |||
| D W L K R L Q K I F P P I L S I | |||
| T D Q Q K V S E I F Q S S K E K L Q G D A K V V S D A F K | |||
| Q A S T G S L L N I L R | |||
| V L S F K T G I I S L | |||
| P Q H E R D V I Y E E E S | |||
| F A K L L A K A L K K A L | |||
| K H H A A Y V N N L N N A L K K | |||
| A A D I F S K F K K D M E V K F A | |||
| P T L L D L F A E D I G H A N Q L L Q L V D E E F Q A L E R | |||
| T S H L M G M F Y R T I R M M E N | |||
| G S D F L I H F I D E | |||
| F V P V F F V V V R R R | |||
| P D I K A Q Y Q Q R W L | |||
| F A K L A K K A L A K L L | |||
| V W H Y A L W S L I Q Q S E I L F A Q | |||
| D S E Q V V H Q L E R L I A R | |||
| D T A F L M E Q L E L R E E L D E I E Q A K | |||
Warning
Remember that this does not necessarily tell us anything about actual biological causality!
E - Serving
In this final section, we demonstrate serving our trained model as a web service and interacting with it using HTTP requests.
Starting the Web Service
To serve the model, use the following command:
eirserve --model-path [MODEL_PATH]
Replace [MODEL_PATH] with the actual path to your trained model. This command initiates a web service that listens for incoming requests.
Here is an example of the command:
eirserve \
--model-path eir_tutorials/tutorial_runs/a_using_eir/tutorial_03_imdb_run/saved_models/tutorial_03_imdb_run_checkpoint_3500_perf-average=0.8001.pt
Sending Requests
With the server running, we can now send requests. For sequence data like IMDb reviews, we send the payload as a batched JSON object.
Here’s an example Python function demonstrating this process:
import requests
def send_request(url: str, payload: list[dict]) -> dict:
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()
payload = [
{"imdb_reviews": "This movie was great! I loved it!"},
]
response = send_request(url="http://localhost:8000/predict", payload=payload)
print(response)
When running this, we get the following output:
{
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.2620399594306946,
"Positive": 0.7379600405693054
}
}
}
]
}
We can also send the same request using the curl command:
curl -X POST \
"http://localhost:8000/predict" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '[{"imdb_reviews": "This movie was great! I loved it!"}]
'
When running this, we get the following output:
{
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.2620399594306946,
"Positive": 0.7379600405693054
}
}
}
]
}
Analyzing Responses
After sending requests to the served model, the responses can be analyzed. These responses provide insights into the model’s predictions based on the input data.
[
{
"request": [
{
"imdb_reviews": "This movie was great! I loved it!"
},
{
"imdb_reviews": "This movie was terrible! I hated it!"
},
{
"imdb_reviews": "You'll have to have your wits about you and your brain fully switched on watching Oppenheimer as it could easily get away from a nonattentive viewer. This is intelligent filmmaking which shows it's audience great respect. It fires dialogue packed with information at a relentless pace and jumps to very different times in Oppenheimer's life continuously through it's 3 hour runtime. There are visual clues to guide the viewer through these times but again you'll have to get to grips with these quite quickly. This relentlessness helps to express the urgency with which the US attacked it's chase for the atomic bomb before Germany could do the same. An absolute career best performance from (the consistenly brilliant) Cillian Murphy anchors the film. "
}
],
"response": {
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.26203984022140503,
"Positive": 0.737960159778595
}
}
},
{
"imdb_output": {
"Sentiment": {
"Negative": 0.8949211835861206,
"Positive": 0.1050787940621376
}
}
},
{
"imdb_output": {
"Sentiment": {
"Negative": 0.018490636721253395,
"Positive": 0.9815093278884888
}
}
}
]
}
}
]
This concludes the sequence tutorial, thank you for making it this far. I hope you enjoyed it and it was useful to you. Feel free to try this out on your own data, I would love to hear about it!