Established Architectures and Pretrained Models
In this tutorial,
we will be seeing,
how we can use
local transformers,
state-of-the-art,
NLP architectures, and
pretrained NLP models with EIR
in order to predict sentiment from text.
We will be using the IMDB reviews dataset,
see here
for more information about the data.
To download the data and configurations for this part of the tutorial,
use this link.
Note that this tutorial assumes that you are already familiar with the basic functionality of the framework (see Genotype Tutorial: Ancestry Prediction). If you have not already, it can also be useful to go over the sequence tutorial (see Sequence Tutorial: Movie Reviews and Peptides).
A - Baseline
After downloading the data,
the folder structure should look something like this
(note that at this point,
the yaml configuration files
are probably not present,
but we will make them during this tutorial,
alternatively you can download them
from the project repository):
eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/
├── conf
│ ├── 04_imdb_globals.yaml
│ ├── 04_imdb_input_longformer.yaml
│ ├── 04_imdb_input_tiny-bert.yaml
│ ├── 04_imdb_input_windowed.yaml
│ ├── 04_imdb_input.yaml
│ └── 04_imdb_output.yaml
└── data
└── IMDB
├── conf
├── imdb_labels.csv
├── IMDB_Reviews
└── imdb.vocab
First we will use the
built-in transformer model
in EIR,
just to establish a baseline.
As always, configurations first!
basic_experiment:
dataloader_workers: 0
memory_dataset: true
n_epochs: 25
output_folder: eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run
valid_size: 0.1
evaluation_checkpoint:
checkpoint_interval: 500
n_saved_models: 1
sample_interval: 500
training_control:
early_stopping_patience: 5
mixing_alpha: 0.2
Note
Training these sequence models can take quite some time if one is using a laptop. If possible, try using a system with a GPU available! If not, set the device setting to ‘cpu’.
Note
You might notice that we have a new configuration in our global config,
mixing_alpha.
The parameter controls the level of
Mixup,
a really cool data augmentation
which is included in the framework,
and is automatically applied to all input modalities
(genotype, tabular, sequence, images, binary data)
when set in the global configuration.
input_info:
input_source: eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/data/IMDB/IMDB_Reviews
input_name: imdb_reviews
input_type: sequence
input_type_info:
sampling_strategy_if_longer: "uniform"
max_length: 128
split_on: " "
min_freq: 10
tokenizer: "basic_english"
tokenizer_language: "en"
model_config:
model_type: sequence-default
embedding_dim: 32
position: embed
pool: avg
model_init_config:
num_heads: 2
dropout: 0.2
output_info:
output_source: eir_tutorials/a_using_eir/03_sequence_tutorial/data/IMDB/imdb_labels.csv
output_name: imdb_output
output_type: tabular
output_type_info:
target_cat_columns:
- Sentiment
As before, we do our training with the following command:
eirtrain \
--global_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input.yaml \
--output_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_output.yaml
Checking the accuracy, we see:
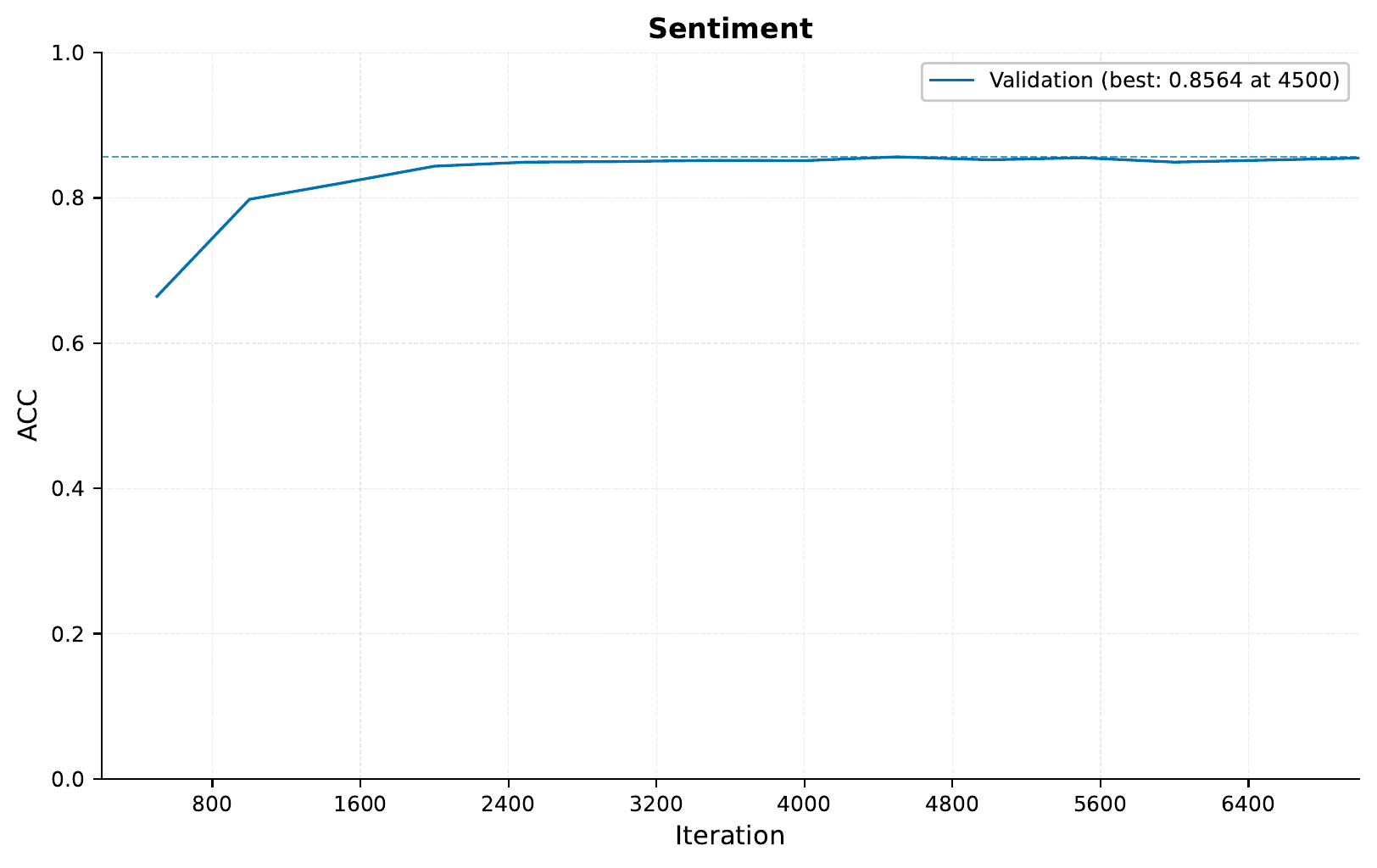
A little better than what we saw in the Sequence Tutorial: Movie Reviews and Peptides, which makes sense as here we are using longer sequences and more data augmentation. In any case, now we have a nice little baseline to compare to!
B - Local Transformer
Transformer models are notorious for
being quite expensive to train computationally,
both when it comes to memory and raw compute.
The main culprit is the quadratic
increase w.r.t. input length.
One relatively straightforward way to get around this
is not looking at the full sequence at once,
but rather in parts (kind of like a convolution).
This functionality is included by default
and can be controlled with the window_size parameter
of the input_type_info field when training sequence models.
Now, let’s try training one such model, using a window size of 64 and increasing the maximum sequence length to 512:
input_info:
input_source: eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/data/IMDB/IMDB_Reviews
input_name: imdb_reviews_windowed
input_type: sequence
input_type_info:
sampling_strategy_if_longer: "uniform"
max_length: 512
split_on: " "
min_freq: 10
tokenizer: "basic_english"
tokenizer_language: "en"
model_config:
model_type: sequence-default
window_size: 64
position: embed
pool: avg
embedding_dim: 32
model_init_config:
num_heads: 2
dropout: 0.2
To train, we just swap out the input configuration from the command above:
eirtrain \
--global_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_windowed.yaml \
--output_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_output.yaml \
--04_imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run_local
Training this model gave the following training curve:

Indeed, increasing the sequence length does seem to help, and using a window size of 64 seems to work fairly well.
C - Established architecture: Longformer
Now, the windowed approach above is perhaps
a quick win to tackle the scaling problems
of transformers when it comes to input length.
In fact, this is such a notorious
problem that people have done a lot of work in finding
cool architectures and methods to get around it.
By taking advantage of the excellent work Hugging Face
has done, we can use these established architectures
within EIR
(big thanks to them by the way!).
The architecture we will be using
is called Longformer,
and as mentioned it tries to approximate full self-attention
in order to scale linearly w.r.t input size.
Tip
Hugging Face has implemented a bunch of other pretrained models and architectures, check this link for an exhaustive list.
To use the Longformer model, we use the following configuration, notice that in the model configuration we are now passing in flags specifically to the LongFormer model:
input_info:
input_source: eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/data/IMDB/IMDB_Reviews
input_name: imdb_reviews_longformer
input_type: sequence
input_type_info:
sampling_strategy_if_longer: "uniform"
max_length: 512
split_on: " "
min_freq: 10
tokenizer: "basic_english"
tokenizer_language: "en"
model_config:
model_type: longformer
pretrained_model: false
position: embed
pool: avg
model_init_config:
num_hidden_layers: 2
hidden_size: 32
num_attention_heads: 2
intermediate_size: 32
attention_window: 64
max_position_embeddings: 1024
Note
The established architectures can have a bunch of different configurations available. Head over to the Hugging Face docs to see which flags they accept and what they do. For example, the LongFormer docs can be found here.
We train with the following command:
eirtrain \
--global_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_longformer.yaml \
--output_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_output.yaml \
--04_imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run_longformer
And get the following training curve:
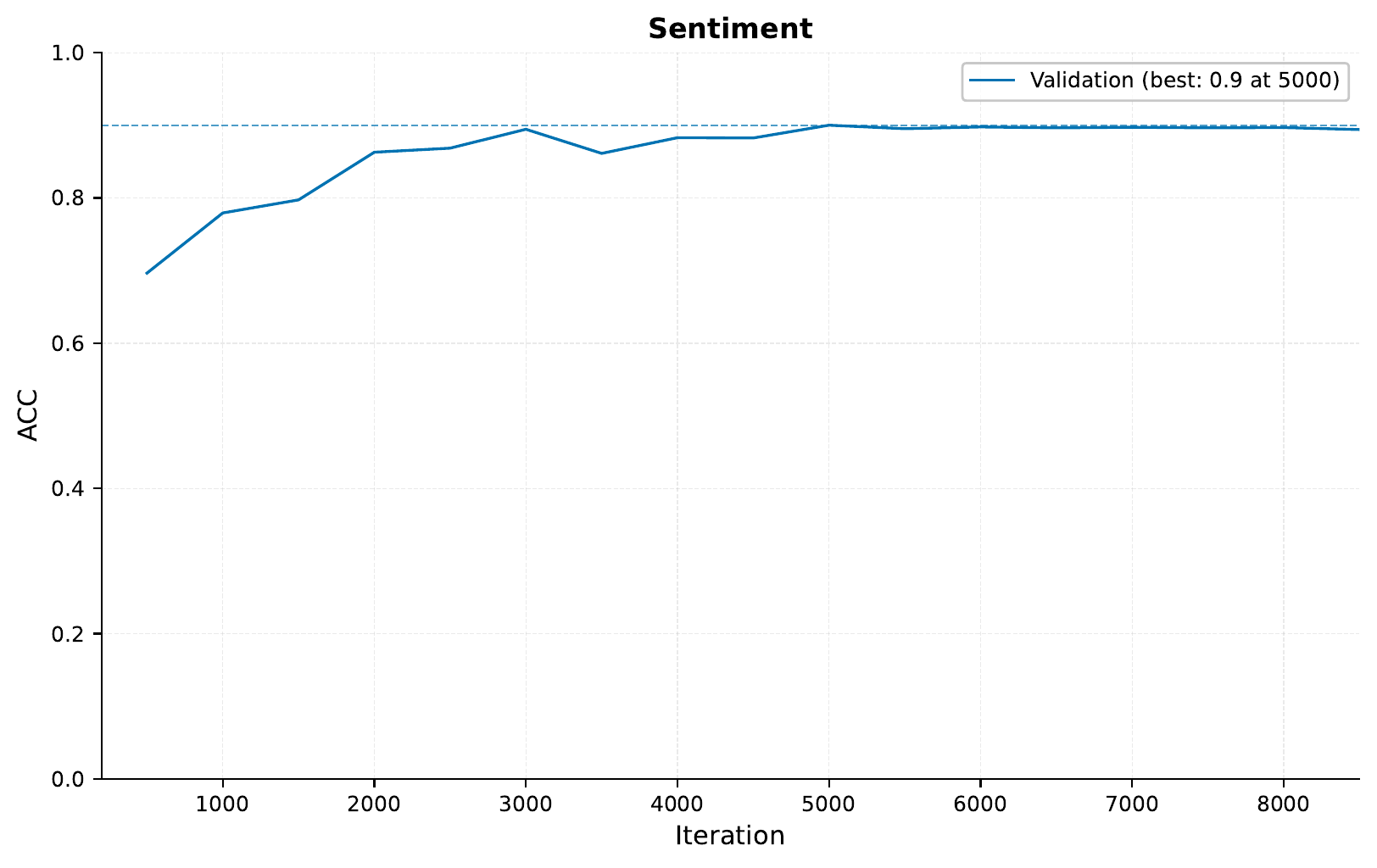
Indeed, we see an improvement on the validation set when using the the Longformer model compared to the first run. There does not seem to be a big difference compared to our local transformer run, Of course, we would have to evaluate on a test set to get the final performance, but this is looking pretty good!
D - Pretrained Model: Tiny BERT
Now, we have seen how we can use cool architectures to train our models. However, we can take this one step further and use a pretrained model as well, taking advantage of the fact that they have already been trained on a bunch of data.
In this case, we will use a little BERT model called Tiny BERT. The approach is almost the same as we saw above with the Longformer, here is the configuration:
input_info:
input_source: eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/data/IMDB/IMDB_Reviews
input_name: imdb_reviews_tiny_bert
input_type: sequence
input_type_info:
sampling_strategy_if_longer: "uniform"
max_length: 512
split_on: " "
min_freq: 10
model_config:
model_type: "prajjwal1/bert-tiny"
pretrained_model: true
freeze_pretrained_model: false
position: embed
pool: avg
Note that when using these pretrained models,
we are generally not configuring things like tokenizers and model_config, as
we use the default tokenizers and configurations used to train the model. EIR will
do this automatically when you leave the fields blank like above. Also notice the flag,
freeze_pretrained_model, if set to False, we will not train the weights of
the pretrained model but rather leave them as they are. This can greatly speed up
training, but can come a cost of performance as we are not fine tuning the this part
of our model for our task.
Note
For the pretrained models, we again take advantage of the excellent work from
Hugging Face. In this case, they have a hub
with a bunch of pretrained models,
which we can use with EIR.
This model is quite a bit larger than the nones we have used so far so here it helps to have a powerful computer. We run this as always with:
eirtrain \
--global_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_tiny-bert.yaml \
--output_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_output.yaml \
--04_imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run_tiny-bert
The training curve looks like so:

The pre-trained model performs quite similarly to our other long context models. However, notice how quickly it reached it top validation performance compared to the other models. Therefore, even though we are using a much bigger model than before, this kind of fine tuning can save us a lot of time!
Note
Many of these pretrained architectures are trained on data that is automatically crawled from the web. Therefore in this case, there might be possibility they have seen our reviews before as part of their training! Of course we are not too concerned for the sake of this tutorial.
E - Combining Models
So far we have seen how can can train bunch of cool models by themselves, but now we will be a bit cheeky and combined them into one big model.
Warning
Make sure that the input_name
under the input_info field
is unique for each input
when doing combining models.
In this case, we will freeze the weights of the pretrained Tiny BERT part of our model.
eirtrain \
--global_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_globals.yaml \
--input_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_windowed.yaml eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_longformer.yaml eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_input_tiny-bert.yaml \
--output_configs eir_tutorials/a_using_eir/04_pretrained_sequence_tutorial/conf/04_imdb_output.yaml \
--04_imdb_globals.basic_experiment.output_folder=eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run_combined \
--04_imdb_globals.basic_experiment.device='mps'
And our performance:
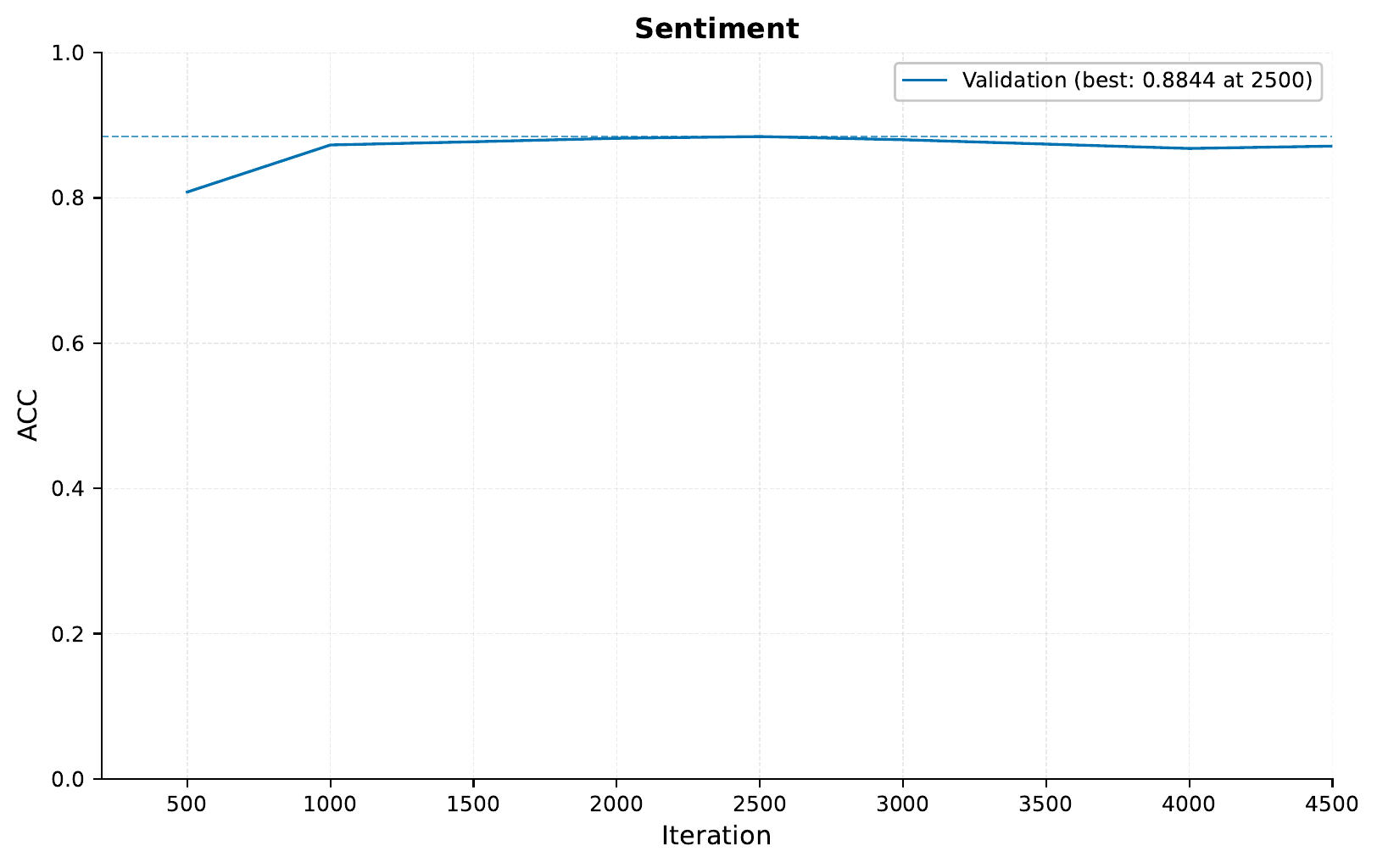
So in this case, we do not see a huge improvement when combining our models. However when relevant, it can greatly boost performance especially in those cases where the different input configurations refer to different modalities, i.e. do not just act on the same input like we did above.
Tip
Combining input configs is not only confined to sequence models or even the same
modalities. For example, to train a model that uses genotype, sequence and tabular
data, just pass the relevant configurations to the --input_configs flag!
F - Serving
In this final section, we demonstrate serving our trained model as a web service and interacting with it using HTTP requests.
Starting the Web Service
To serve the model, use the following command:
eirserve --model-path [MODEL_PATH]
Replace [MODEL_PATH] with the actual path to your trained model. This command initiates a web service that listens for incoming requests.
Here is an example of the command:
eirserve \
--model-path eir_tutorials/tutorial_runs/a_using_eir/tutorial_04_imdb_run_combined/saved_models/tutorial_04_imdb_run_combined_checkpoint_2000_perf-average=0.8902.pt
Sending Requests
With the server running, we can now send requests. For this model, we send different features extracted from the same input text in a batched format.
Here’s an example Python function demonstrating this process:
import requests
def send_request(url: str, payload: list[dict]) -> dict:
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()
payload = [
{
"imdb_reviews_windowed": "This movie was great! I loved it!",
"imdb_reviews_longformer": "This movie was great! I loved it!",
"imdb_reviews_tiny_bert": "This movie was great! I loved it!",
},
]
response = send_request(url="http://localhost:8000/predict", payload=payload)
print(response)
When running this, we get the following output:
{
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.059643134474754333,
"Positive": 0.9403569102287292
}
}
}
]
}
We can also send the same request using the curl command:
curl -X POST \
"http://localhost:8000/predict" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '[{"imdb_reviews_windowed": "This movie was great! I loved it!",
"imdb_reviews_longformer": "This movie was great! I loved it!",
"imdb_reviews_tiny_bert": "This movie was great! I loved it!"}]'
When running this, we get the following output:
{
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.059643134474754333,
"Positive": 0.9403569102287292
}
}
}
]
}
Analyzing Responses
After sending requests to the served model, the responses can be analyzed. These responses provide insights into the model’s predictions based on the input data.
[
{
"request": [
{
"imdb_reviews_windowed": "This movie was great! I loved it!",
"imdb_reviews_longformer": "This movie was great! I loved it!",
"imdb_reviews_tiny_bert": "This movie was great! I loved it!"
},
{
"imdb_reviews_windowed": "This movie was terrible! I hated it!",
"imdb_reviews_longformer": "This movie was terrible! I hated it!",
"imdb_reviews_tiny_bert": "This movie was terrible! I hated it!"
},
{
"imdb_reviews_windowed": "You'll have to have your wits about you and your brain fully switched on watching Oppenheimer as it could easily get away from a nonattentive viewer. This is intelligent filmmaking which shows it's audience great respect. It fires dialogue packed with information at a relentless pace and jumps to very different times in Oppenheimer's life continuously through it's 3 hour runtime. There are visual clues to guide the viewer through these times but again you'll have to get to grips with these quite quickly. This relentlessness helps to express the urgency with which the US attacked it's chase for the atomic bomb before Germany could do the same. An absolute career best performance from (the consistenly brilliant) Cillian Murphy anchors the film. ",
"imdb_reviews_longformer": "You'll have to have your wits about you and your brain fully switched on watching Oppenheimer as it could easily get away from a nonattentive viewer. This is intelligent filmmaking which shows it's audience great respect. It fires dialogue packed with information at a relentless pace and jumps to very different times in Oppenheimer's life continuously through it's 3 hour runtime. There are visual clues to guide the viewer through these times but again you'll have to get to grips with these quite quickly. This relentlessness helps to express the urgency with which the US attacked it's chase for the atomic bomb before Germany could do the same. An absolute career best performance from (the consistenly brilliant) Cillian Murphy anchors the film. ",
"imdb_reviews_tiny_bert": "You'll have to have your wits about you and your brain fully switched on watching Oppenheimer as it could easily get away from a nonattentive viewer. This is intelligent filmmaking which shows it's audience great respect. It fires dialogue packed with information at a relentless pace and jumps to very different times in Oppenheimer's life continuously through it's 3 hour runtime. There are visual clues to guide the viewer through these times but again you'll have to get to grips with these quite quickly. This relentlessness helps to express the urgency with which the US attacked it's chase for the atomic bomb before Germany could do the same. An absolute career best performance from (the consistenly brilliant) Cillian Murphy anchors the film. "
}
],
"response": {
"result": [
{
"imdb_output": {
"Sentiment": {
"Negative": 0.05964311584830284,
"Positive": 0.9403569102287292
}
}
},
{
"imdb_output": {
"Sentiment": {
"Negative": 0.9672294855117798,
"Positive": 0.03277059271931648
}
}
},
{
"imdb_output": {
"Sentiment": {
"Negative": 0.02780037745833397,
"Positive": 0.9721996188163757
}
}
}
]
}
}
]
If you made it this far, I want to thank you for reading!